

对于未来我们也一直都是抱着非常乐观和让人期待的调调和大家说长道短,但如果您是一直以来对于人工智能和机器人之类的话题有天然的抗拒,那么也许,今天的话题对缓解您的恐慌并不会有太大的帮助⋯⋯
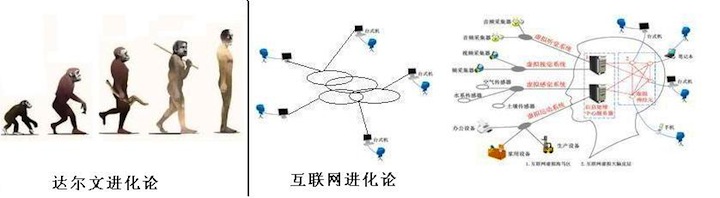
关于人类的进化规律,最大众化的一个观点是达尔文的进化论。有没有想过,它和互联网、计算机科学、科技什么的,会不会有什么关系?
编辑、作者: Vivian Peng @DamnDigital
Cover Image: Wang Qi@DamnDigital
(原创内容,转载请注明来自DamnDigital)
Computers, Data, information, web, networks, social network, sementic web, cloud, 物联网⋯⋯所有这些都是常常被我们提到的几个概念,当我们把这些词放在一起,在一起看,想问的是:“究竟这些东西之间,有什么联系?所有这些在明天将如何变化发展?”
在知乎上,常常会看到有人会问这样一个问题:“互联网下一个十年会是怎样的?”,“互联网下一个突破会是什么?”、 “互联网会不会真的进化出智慧?”⋯⋯
人们前所未有地对这些名词充满了强大的好奇心和求知欲望。 我们学习历史,其实是为了更好地迎接明天;那么通例可循,一定很想知道,互联网发展的历史,有没有什么特别的规律?
Internet evolution – Where is “there” and how do we get “there” from here?
—— 引用了互联网最红的大叔Kevin Kelly的一句话作为开始。
我们一直探讨,各种各样的创新科技,人机交互技术的变更,试图发现其背后的必然关系,寻找出一种便于人类更好理解自身未来的规律理论。今天,我们暂且跳过创新科技生活应用的话题。
还是回头说起当时我们曾提到过的,关于科技的进化一题:
2006年,Kevin Kelly在TED上一则惊动世界的演讲《How Technology Evolves》中,他把技术本质的研究转化成一个终极问题:技术的野心是什么?他的结论是: 技术与生物世界的进化史一样,最终将逐渐蔓延至世界各地的任何一个角落,人们的未来生活将无处不存在技术的渗透。(Complexity, Diversity, Specialization, Ubiquity, Evolvability.)
撇开技术,提到与我们更为息息相关的数字互联网的发展,从最早的Internet 直到Web2.0,移动互联网,直到明天的Web 3.0, 物联网,语义网⋯⋯直到今天,我们再回头去看数字互联网一路的创新与发展轨迹,究竟,会不会有什么根本性的规律呢?
Kevin kelly大叔最畅销的《失控》一书,曾经是《黑客帝国》所有演员必读的3本书之一。这本16年前出版的书准确地预测到了今天的云计算、物联网等最前端的互联网科技,凯文本人甚至大胆预言以PC为中心的微软会成为第一个消失的IT巨头。
对于互联网的进化, Kevin Kelly大叔同样有自己的观点:
Kevin Kelly on the next 5,000 days of the web
凯文·凯利谈未来5000天后的网络世界
All these computers, all these handhelds, all these cell phones, all these laptops, all these servers — what we’re getting out of all these connections is we’re getting one machine. … We’re constructing a single, global machine.” (Kevin Kelly)
KK大叔说了:“人类每天有1000亿次点击,整个互联网有55万亿个链接,这差不多是人脑中神经突触的数目了。
此外,1000万亿个晶体管也接近人脑中神经细胞的数目。初步统计,这些东西相当于2万兆根神经纤维。这个机器的规模和复杂程度等等,和人脑很接近。因为人脑的运作方式基本上和网络的运作方式一样。”
Kevin Kelly 大叔是在2010年提出的的互联网进化观点,在我们看来已经相当彻底。但是其实,中国学者早在3年前就已经提出类似言论:
中国科学院虚拟经济与数据科学研究中心研究员、中科院计算机博士、威客网负责人刘锋曾经与他的团队在2007年就开始研究早期的互联网进化论雏形。
他们提出:
“历史表明人类大脑的延伸和联结一刻也没有停止,互联网就是虚拟的人脑。”
可以支持这一判断的历史经验包括:从人类的发展史看,人类的进步就是器官不断延长和连接的历史:棍棒延伸了双臂,石头延伸了拳头,汽车延伸了双腿,望远镜延伸了眼睛,电话线延伸了耳朵,公路、铁路使人类四肢最终实现“联网”。
究竟我们的学者发现了什么呢?我们不妨听一听他们的见解:
互联网进化论——互联网世界的“达尔文进化论”?
以下关于“互联网进论”内容均来自:
中国科学院互联网进化与网络智慧研究中心:互联网进化论
中科院虚拟经济与数据科学研究中心客座研究员、互联网进化论创始人@刘锋互联网进化论
中国科学院学者,也就是互联网进化论的提出者,对于互联网进化论的观点主要为:
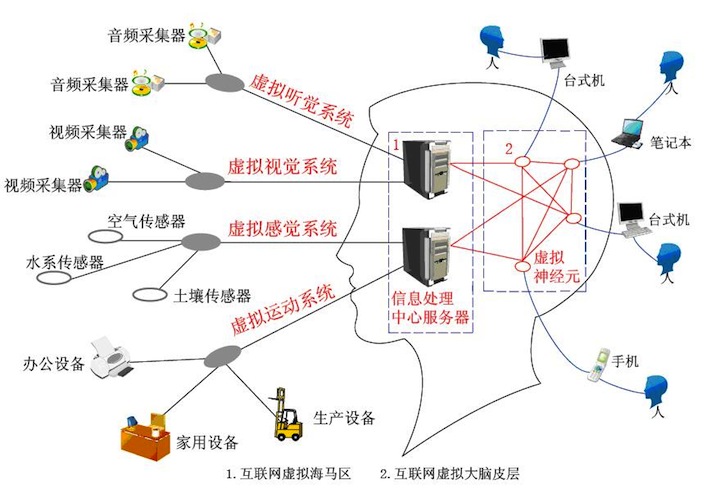
“互联网正在从一个原始的,不完善,相对分裂的网络进化成一个统一的,与人类大脑结构高度相似的组织结构,它将同样具备自己的虚拟神经元,虚拟感觉、视觉、听觉、运动,中枢,自主和记忆神经系统。我们将互联网这一结构命名为互联网虚拟大脑。互联网虚拟大脑的不断成熟将对神经学产生重大的启发式影响。“
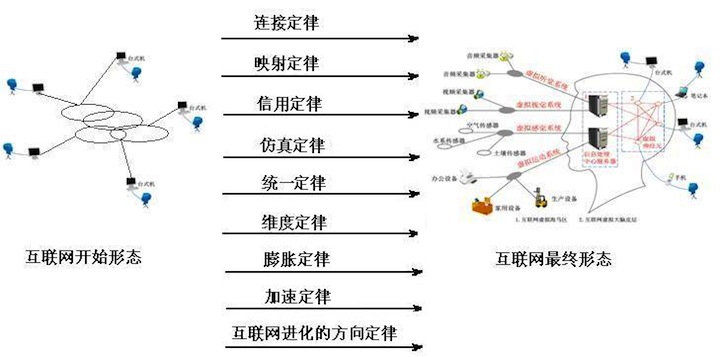
1、从人类的发展史看,人类的进步就是其若干运动和感觉器官不断延长和连接的历史。
2、从1753年C”M在“苏格兰人”杂志上阐述“电流通信机”开始,人类用216年的时间为互联网的诞生作技术储备
3、1969年互联网诞生,人类第一次实现人类大脑的最初级联网
4、70年代到80年代初,互联网虚拟大脑初具雏形,拥有电子公告牌,电子邮箱,FTP,原始游戏,网络应用软件五大功能。
5、80年代到21世纪初,电子公告牌九个重要功能发布新闻,求购商品,心情感悟描述,互动问答,热点点评,帖子修改权,注册信息,交换物品,资料索引功能一个个分离出去,形成互联网虚拟大脑的功能区。
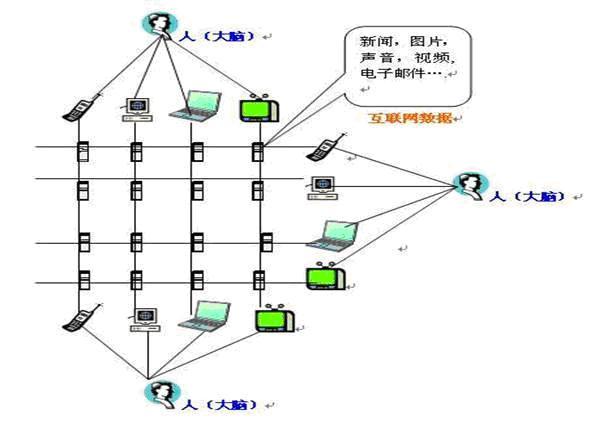
6、从21世纪前十年,电子公告牌及其分离的功能区开始和电子信箱,FTP,网络游戏,网络应用软件进行融合。
7、笔记本电脑,手机,无线互联网的出现不断延长人类大脑与互联网的接驳时间。
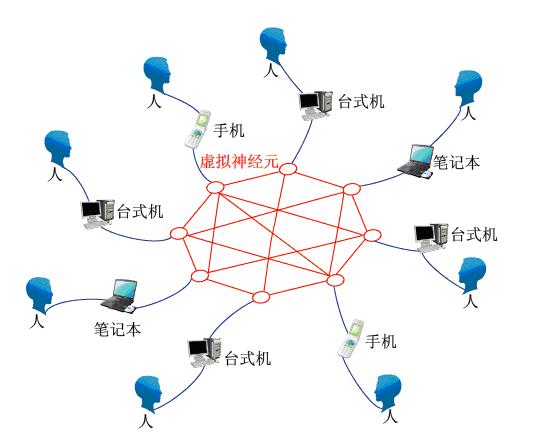
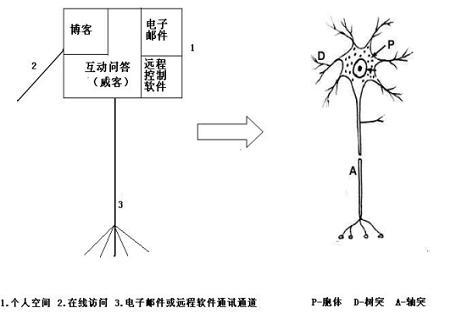
8、博客,威客(基于知识与智慧观点分享的应用/平台),应用软件和电子邮箱等功能开始进一步融合形成互联网的虚拟神经元-大脑映射区。与现实中的人进行信息同步。
9、随着互联网带宽的增加,文字,图片,平面操作系统为主的二维互联网虚拟世界开始向视频,声音,三维应用系统为主的三维互联网进化。
10、随着互联网虚拟神经元,虚拟视觉,虚拟听觉,虚拟感觉,虚拟记忆系统的完善,互联网最终将进化成一个类人脑组织的结构,这一结构对于揭开人脑之谜将起到启发作用。
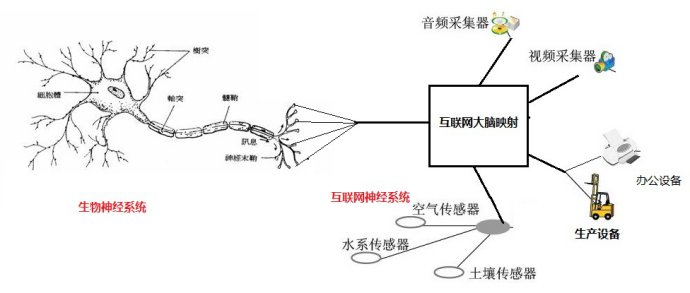
互联网的每一个创新,无论其贡献者是否意识到,其背后都显露出互联网进化力量的推动。根据此,该理论提出者认为:互联网是由物理网络、服务器节点、在服务器节点和物理网络,终端设备和人的大脑之间流动的数据、物理网络末端的终端设备、操作终端设备的人等五个要素组成的集合体。
互联网进化论:互联网进化的九大规律:
互联网与神经学交叉对比的问题探讨
一般认为互联网诞生与1969的美国,从那时起,人类各个领域都受到剧烈和广泛的影响。面对互联网的迅猛发展,需要面对二个问题:
第一 互联网的发展规律和最终结构是什么?
第二 互联网将会给哪个领域带来科学突破?
从2005年开始,中科院相关研究人员对互联网进行了大量观测,发现互联网和大脑具有很强的相似性。因此在2007年的一篇论文中提出互联网与神经学的交叉对比问题。一方面可以预测互联网未来的发展动向和最终结构;另一方面互联网有可能成为神经学研究的参照物,为彻底解开人脑之谜提供突破口。
2005年,中科院对互联网进行研究时,发现了电子公告牌功能分裂现象,2006年发现分裂后的电子公告牌功能,又形成以“个人空间”为代表的互联网新应用,非常类似人脑中的神经元结构。
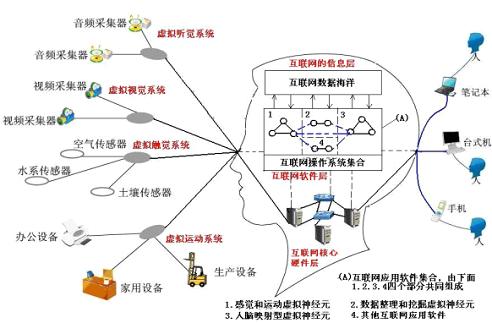
Google的街景系统,中国水利部的防汛抗旱传感器网络,医院的远程手术让我们联想到生物的视觉,躯体感觉和运动神经系统。到2008年正式发表论文,绘制出这样一张互联网虚拟大脑结构图。
2008年,这一学说的研究者与其团队正式将这一观点相关文献向美国ACM期刊投稿,结果被拒。
从2008开始到2010年,中科院相关研究人员在论文中共提出11项大脑中可能存在的类互联网应用,它们分别是:
1)大脑中类SNS应用
2)类电子商务应用
3)类twitter应用
4)类威客(witkey)应用
5)类博客应用
6)类维基百科应用
7)类地址编码系统
8)类搜索引擎
9)大脑的路由协议
10)类互联网信用体系
11)类互联网信息筛选,整理和推荐机制
2011年,研究者进一步研究,深入提出了更为详细的互联网与神经学的交叉对比,以论证以目前互联网个人空间应用为基础,扩充并预言了成熟后的互联网神经元结构。
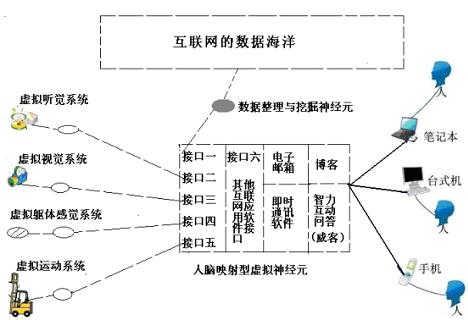
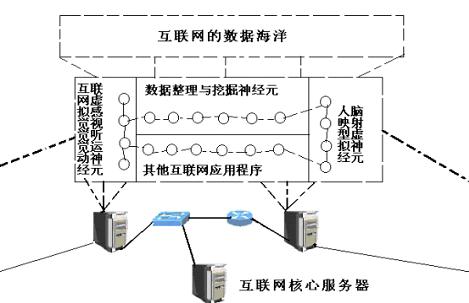
互联网虚拟中枢神经系统示意图 图片来源
对这一观点有兴趣的朋友可以点击查看更多详细的研究资料:查看互联网进化论
互联网和达尔文真的有关系吗?
学者们认为人脑是自然选择的产物,而人又是自然的一部分,人的选择是自然选择的一种,那么在科学研究和商业竞争的推动下,人创造的互联网类脑结构应该也是是自然选择的产物。“人“这个要素连接了互联网的进化与达尔文进化论.
关于互联网的进化规律方面的学说,并不太多,国内最突出的研究目前也只有这个方向,并且还没有得到正式的确实,处于研究阶段。对于此,并没有太多评论。只是有一个问题:
如果互联网的进化规律与模式真的是类神经系统,似人类大脑发展过程,不该仅仅从结构上的相似来进行论证。人类神经系统的发展,是生物学上的演进过程,包括三大进程:遗传——突变——自然选择。无一生物例外。
如果互联网真的是类神经系统,应该具有这些进程的天然特征。计算机互联网在这方面,真的很难来论证,遗传自何处,演进过程是人给定的,还是真的自然选择呢?这类命题,真的无法用非常可观的系统数据来进行论证。
当然,这一观点给予我们最大的参考价值是,让我更相信,互联网的进化过程必然是人类自身欲望和人类智慧的体现。
⋯⋯
可是,随着KK大叔之类的国际权威言论人士也开始逐渐对互联网信息科学自身进化的能力开始认定不已的时候,这样的说法和追随者越来越多。记得曾经我们曾提过,未来怎么样其实都是我们有意无意之中,根据自己想要的样子一点点塑造出来的。随着机器自身进化类似的观点不断浮出水面,日趋主流的同时,我们不由开始焦虑这一发展的负面效应,一个典型的负面焦点问题就是: 人工智能和机器人。 如果,机器,技术, 互联网具有自身进化的能力。那么,会不会有天,机器的智慧超越人类?
机器有智慧还不算严重的,如果说,机器已经能够实现自我繁殖的能力,代代相传,岂不是更可怕?!⋯⋯
可是,这已经不是什么科幻的话题了,因为科技上,已经实现了:

Mystery philanthropic robots(来自影片《鬼使神差》*batteries not included,1987)
会繁殖的机器 Self-Replicating Machine
哥伦比亚大学地球工程中心的教授克劳斯· 拉克纳尔(Klaus Lackner)曾经在洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)工作。那时他和他的朋友,威斯康星大学的粒子物理学家克里斯托弗·文特(Christopher Wendt),正在喝啤酒聊天。一个念头突然冒了出来:“怎样解决全球变暖问题?”
他们都知道,这不是一件小事。他们打算把空气中的二氧化碳转变成碳酸钙——石灰石、汉白玉、白垩,都是这种东西。从空气中提取二氧化碳然后变成固体的工作量和所需要的资源都是惊人的,不能指望有人投资或者国家拨款,所以他们只好转而寻求其他办法。
例如……一个全自动的转化过程。假设一台机器。它能够复制自身。它可以把太阳能转化为所需的电能。它可以很容易地获得制造它的原料。这样如何?
听起来很不错。机器数量将会以倍数递增,一台变成两台,两台变成四台,然后是八台、十六台。这像是一个细胞一样不停地分裂,而无穷无尽的太阳能将会让它们不停地繁殖下去,直到被制止为止。
太阳能不是问题,而一台机器所需要的原料无非是铁、铜、铝、硅、碳这样的常见元素罢了,这些东西遍地都是,只要提取出来就行。只有一个问题:怎样让机器自我复制?
这个问题曾经难倒过笛卡尔,不过我们现在已经有了答案。
在20世纪40年代晚期,冯·诺依曼(这个大叔!!!又是他!!!)已经初步解决了这一问题。当时他在加利福尼亚州帕赛迪纳的海克森研讨班上做了一系列演讲,要解决的核心问题就是“机器要怎样才可以自我复制?”

picture source: http://ysfine.com/wigner/neumann.html
冯·诺依曼认为: 任何能够自我繁殖的系统,都应该同时具有两个基本功能。第一,它必须能够构建某一个组成元素和结构与自己一致的下一代;第二,它需要能够把对自身的描述传递给下一代。他把这两个部分分别叫做“通用构造器”和“描述器”,而描述器又包括了一个“通用机器”和保存在通用机器能够读取的介质上的描述信息。
这样,只要有合适的原料,通用构造器就可以根据描述器的指示,生产出下一台机器,并且把描述的信息也传递给这台新机器。随后,新机器启动,再进入下一个循环。
—— 这就是最早期的关于自我繁殖的机器的历史缘起。
那么,在近代,这方面的发展就更不得了了。我们都知道的机器人,无疑,是机器进步的一个重大突破。
虽然比尔·盖茨做出了不少错误的预言,但是这次看起来还是比较靠谱的。家用卫生机器人已经不是什么稀罕东西了,最近还有一些企业推出了机器人厨师。小朋友们抱着会撒娇的机器恐龙,科技馆门口站着机器迎宾小姐。甚至还有人信誓旦旦地认定,到了2050年,和机器人结婚都不在话下。
实际上,能够繁殖的机器并不少见——比方说我们的工业流水线。在你看到这里的那一瞬间,世界上有大量我们看不见的机器人正在厂房里忙碌。日本是世界上工业机器人最多的国家,世界上一半的工业机器人都在日本。那些机器人和我们在卡通片中看到的不太一样——看起来只是一支机械手臂,没有表情丰富的脸和健美好看的身段。这些机器人日复一日地在生产线上焊接组装手机、电脑、以及……更多的机器人——但是同样没有自我意识。这种机器人看起来要安全得多。也许很快,我们在家里也可以这么做了。
img source: life boat
RepRap:是三维打印机原型,更是可自我复制的开源机器

RepRap可以通过电脑的指令来制造实体的零件,然后由操作者手工装配。实际上,它的核心部件就是一个三维打印喷头,使用融化的塑料来制造零件,或者使用融化的低熔点合金来打印电路。因为并非所有的部件都可以用塑料或者这种合金来制作的,因此一些零件不得不采用其他材质。看起来,这似乎距离我们想象的那种自我复制机器人似乎有点远。可是,你要知道,机器人的自我复制原理,几乎和RepRap的原理相似。再想想,我们曾经在2012的CES专题文章中所说的:三维打印机已经成为现实⋯⋯ 这么连起来一想,不禁有点毛骨悚然。
2005年,美国康奈尔大学的科学家真正向全世界验证了机器人可以做到自我复制、自我修复。据说,美国国家航空航天局对这一技术很感兴趣,期待自我复制的机器人将来在太空大显身手。
美国康奈尔大学研制的能自我复制的机器人,看起来更像一个托儿所里的玩具,而不像星际大战里的机器人。它由4块智能模块组成,目前还不能走动,也不能说话。但该机器人的发明人称,它证明了机器能够通过编程来实现自我复制。这是观念上的一个突破,即机器人能够在离开人类的环境下独立生存。
组成机器人的智能模块大小为10立方厘米,模块间可自由旋转120度。模块外表面配有电磁铁,这样模块之间就可以由磁力强弱来拼装组合或分开。这种设计下的机器人可以自由拼装成各种形状,如塔、直角、正方形等。每一块模块里还有一个微型计算机芯片,其中含有组装时的具体指令。
该机器人自我复制的步骤是:首先,机器人弯下腰,把1个模块放在桌子上,作为自己复制品的“头”。随后,它将身子侧到另一边,利用电磁铁的吸引力吸取1个新模块放在复制品的“头”上。机器人根据情况翻转这些模块,按照以上步骤进行重复工作,最终,一个新的、外形与原机器人相似的机器人拼装组合成功,整个过程耗时2分34秒。
领导此项研究的霍德·利普森表示,尽管这个机器人自身还有很多局限,但它至少证明了机器做到自我复制是可能的,而不是只有有机体才能做到。
霍德·利普森说:“能自我复制、自我修复的机器人甚至能在人类无法适应的环境中装配出一整台新的机器。最令人激动的就是在太空中的应用前景,比如探测火星。”
据利普森讲,这项研究得到了广泛的支持,资助方之一就是美国国家航空航天局。他说:“人们对这方面的兴趣越来越大,他们想要那种既能诊断问题、又能自我修复的高性能机器人。举例来说,假如一个探测火星的机器人出了毛病,你肯定想就地修好它。人们可不希望因为机器人出点小问题就放弃整个探测任务。”
而且,机器人自我复制和自我修复技术的应用领域不只在太空,在战争地区或损坏的核反应堆中,人是不容易生存的,但机器人就可以。
除此之外,在近两年,各种机器人的技术不断在人们的没有意识到的眼皮底下迅速发展,各个国家目前都已经实现了具有人工智能的机器人,以及机器人实现自我复制的能力。

IBM公司的一个研发小组在一块镍板上,通过扫描隧道显微镜用35个氙原子拼出了“IBM”的字样
(笔者已经开始有点密集恐惧上头了⋯⋯)
自我复制一旦失控?
尽管,科学家们都不断声称,会严格对这些技术加以管理和利用,但是依然组织不了人们不断发生一个惊恐的疑问:如果自我复制失控了呢?
正如我们在每一台机器上面都安装了一个开关一样,任何一台能够复制的机器必然也有一个停止复制的控制机制。在我们体内,正常的细胞每分裂一次,线粒体的端粒就会缩短一次,当断于临界长度时,细胞就不再分裂,而会衰老死亡。计算机软件中往往也有这样的计数器程序,特别是在一些试用版软件中。同样的,对于自我复制的机器,也可以采用类似的技术来防止其无限制地复制下去。

img source: future converged
万一某天,突然有个变态的大叔跑进实验室,或者某天某位科学家突然精神失常,于是就释放了这种无限繁殖的机器,那不就失控了?万一机器在某天突然拥有自我意识(完全不怀疑这一天的到来),变成了天网,甚或将我们的世界变成了The Matrix呢?这些依然是未知数。我们只能寄希望于科学家们的才智,姑且认为每当这个世界面临崩溃的边缘的时候,他们有能力将这个世界重新拉回正轨。
科学家们并没有去回避危险,是因为他们相信能够控制他们的造物。说起来,人类的整个发展史,不也是走过了一条类似的道路吗?
人算终究不如天算⋯⋯
其实,人类智慧无穷,怎么会栽在机器的手上呢?!⋯⋯ 一起进化吧!记得多多缅怀伟大的达尔文大叔⋯⋯
参考资料:
转载请在文章开头和结尾显眼处标注:作者、出处和链接。不按规范转载侵权必究。
未经授权严禁转载,授权事宜请联系作者本人,侵权必究。
本文禁止转载,侵权必究。
授权事宜请至数英微信公众号(ID: digitaling) 后台授权,侵权必究。




评论
评论
推荐评论
暂无评论哦,快来评论一下吧!
全部评论(0条)